The one data platform to rule them all… but according to whom?
An overview of recent data startups based on popular end users

Introduction
Especially in recent years, mind-boggling amounts of data are being created & modified to guide companies’ business decisions, and unsurprisingly a plethora of startups have emerged to streamline each part of the data journey. However, as per common startup guidance, it’s never a good idea to limit the total available market (TAM) you can reference in your investor pitches, so the majority of these startups have one thing in common - they are each eventually planning to become the “all-in-one, single source of truth, only system of record you’ll ever need - really this is it I swear - data platform.”
Of course, this currently can’t be true about all of them (and most are realistic about their near term market). No universal platform currently exists for accomplishing all of the jobs-to-be-done around collecting, storing, manipulating, visualizing, reporting, and acting on data at the necessary scale of a fast growing startup, much less a mature organization. Until recently, I was an early engineer turned the first product manager at Scale AI. For me to make any progress with a new source of data there, I had to work with many teams who each had their own favorite tools - perhaps I’d start with the infrastructure team to figure out data storage & work out latency bugs, then with our data analytics team to load the data into a warehouse & utilize various visualization tools, and lastly execs or the operations team to act on the reports and alerts. Add another few meetings or weeks if there’s an A/B test or ML model in the middle of all of this.
So, recently starting as an investor at Founders Fund and seeing so many “data platforms,” I decided to do a deeper dive into where each excelled, as well as how they interacted with each other. I think the clearest way to view the ecosystem is through what user persona each tool is implicitly targeting by making that persona’s day 10x better. Perhaps the tool sells into another persona, but I’m most curious about the tool’s true “champion”, the people who can’t imagine their life without it. There are a few common users involved in the process of utilizing data, and they each have distinct responsibilities. (Sidenote - these responsibility distinctions definitely aren’t perfect -- there are problems with the current division -- and data team organizational structure is challenging.) I find the following graph useful to illustrate what each role is generally concerned with, as well as the flow of data from its original hard-to-use raw state to becoming a perfect metric that can magically provide all of the answers…

Each new data startup can address at least one concern from one persona really well, and some can help with adjacent concerns from the same user or an adjacent user. With that in mind, I can build out an imperfect map of the recent data startup ecosystem with sample logos.
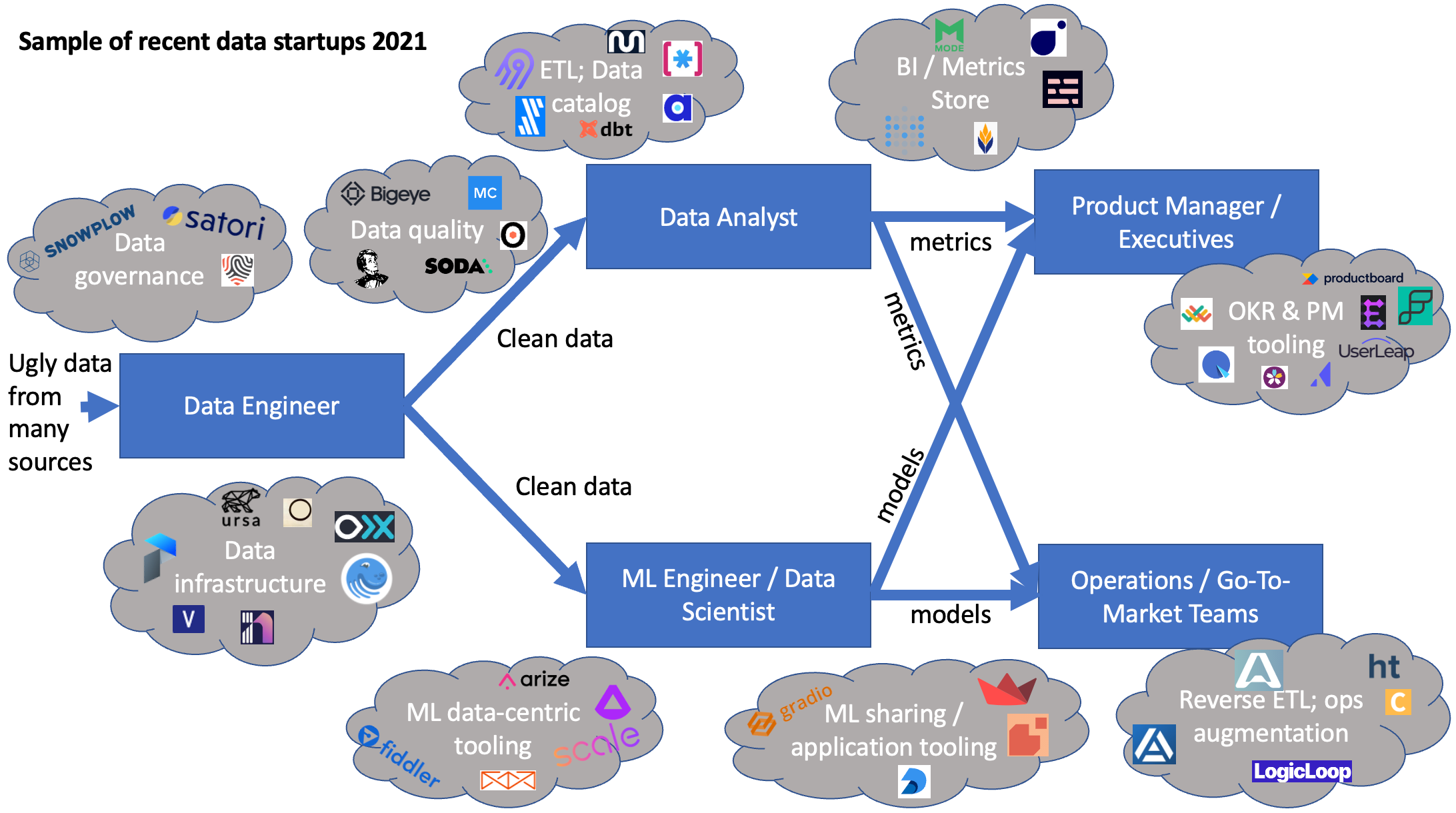
This is necessarily a snapshot in time - let’s say mid-2021. I fully expect many of these incredible teams to expand their reach inside and across personas. However, with this graphic in mind, some interesting questions to consider when predicting the space’s evolution are:
Which tools will become more mission critical to their most popular user persona? Which generalizes well across that persona at different types of companies?
Which particular use cases (one concern of one persona) will grow rapidly over time? Which particular use cases have clear incumbent(s) with obvious flaws?
Which tools have the greatest likelihood of becoming useful for multiple types of users or multiple use cases for the same user? Where are there clear advantages (product, sales, etc.) from offering multiple use cases together?
I definitely don’t have all of the answers to the relative strategic importance of these questions, but in particular - there are advantages & disadvantages to focusing on one persona. The advantage to expanding across multiple concerns for the same persona - you become even more essential and hard to displace for that type of user. The advantage to expanding across multiple personas - though perhaps not as mission critical for each user, you have more opportunities for upselling & less reliance upon any particular team’s budget.
Ultimately, the startups with the smartest approach and an amazing team & product will have much better chances of attaining their “universal data platform” vision. No company wants to have a million external vendors powering their data stack, so the startups that can find technical & sales advantages between use cases (and integrate smoothly with use cases they don’t yet support) will triumph.
Whether you’re a founder expanding across use cases, an operator evaluating new tools, or just a curious investor like me, I hope the following user-centric framework & market commentary is helpful.
Data Tooling Overview by End User
Data Engineer

Data storage costs & compute
These tooling categories- known as core data infrastructure- are universally agreed upon to be mission critical, and therefore have many incumbent solutions. However, the correct choices for a particular company depends on their amount of data & service-level objectives (SLOs), which require different levels of product sophistication to handle. DevOps engineers might also handle or share these responsibilities, as “data engineer” is a relatively new role for many companies.
Generally, in my speaking to engineers, they are increasingly wary of being tied to a particular cloud as well as of the developer unfriendliness & high cost of some widely-used cloud-provider specific solutions. The overarching sentiment is that though things will eventually work, they could be a lot better - faster to try out, more transparent, cheaper, and more intuitive to maintain & scale. The fact that most of a company’s data budget is already spent on data infrastructure as well as the increasing consensus around the benefits of a cloud data warehouse makes it even more attractive for startups to tackle pain points here.
Lastly, infrastructure engineering teams are critical and hard to hire! There is a massive opportunity to lower the amount of headcount and DevOps expertise required to set up data infrastructure by making all of the above tooling categories much simpler to create and maintain. For example, the days of engineers writing lots of complicated orchestration for data pipelines might be beginning to end by giving data analysts the power of new ETL tooling.
Data quality & freshness
“Data observability” (a term perhaps coined here), the ability to know what’s wrong with your data & fix it, has only in the past few years become a category where startups look at external providers. However, even with the recency of the category, there are now a large number of well-funded startups to evaluate. The idea definitely makes sense - bad data probably costs us all an astronomical amount of money & wastes a ton of time. If a solution can successfully plug into all parts of a company’s data stack, it can theoretically catch most data errors even before they break production.
However, the devil is in the details, as each startup makes trade-offs in a new market where no standards exist. Will the winning solution be one that offers the best out-of-the-box data anomaly detection, or one with excellent UX around creating customized data quality rules? Will it be a thriving open source community where many data engineers at different companies contribute types of data quality checks, or a traditional top-down enterprise company with a large team of engineers writing them all internally? Will a best-in-class machine learning team develop a 10x better way of detecting suspicious data that makes their solution the no-brainer? In my research talking to customers of many of these providers, many data teams are very early in their data observability journeys. They are excited about their current solutions, but eager to see how the wide array of products develop.
Most solutions mentioned here are in monitoring, which is necessarily helpful after the fact. It alerts you that something broke so that you can reactively fix it. Other solutions have more of a proactive focus, either through providing ways of preventing common errors in the code or through offering debugging features like visualizations of data lineage & documentation.
Data security
Data governance is the process of managing the availability, usability, integrity and security of the data in enterprise systems, based on internal data standards and policies that control data usage. Given the overlap with the “data observability” category, I’ll focus on the compliance / security aspects. The term “data governance” was likely popularized in the early 2000’s, and it’s something on the minds of any company dealing with sensitive data or seeking compliance with regulations like GDPR & CCPA or standards like SOC 2 & HIPAA. Companies are investing between 2.5% and 7.5% on average of their IT spend on data governance, many with incumbent providers like Collibra, Informatica, Alation & more.
A potential opportunity here is to provide a solution for startups that want more educational & out-of-the-box solutions on their journey to major regulatory milestones. Talking to data teams, many would love more data governance capabilities ideally from a provider they already have, perhaps “nudges” or automated capabilities with instructional content on how to best hit future security & compliance goals. An adjacent greenfield area is “synthetic” data generation, where noise is added to sensitive data so that it can be used in a compliant way to test or optimize production systems.
Data Engineer & Analyst
Lineage & documentation (for debugging / metric building)
The concept of seeing how your data is being calculated and being used downstream isn’t new, but large incumbents like Collibra, Informatica, & Alation can be challenging to set-up and expensive to use. Many large tech companies have built internal solutions as a result, and startups & OSS have begun to rise to the challenge of providing useful “data discovery” platforms.
It is imperative for these companies to figure out the fastest time-to-value way of providing a holistic view of all of an organization’s data (which is really challenging given the volume of sources), as well as offering excellent UX around onboarding new team members, debugging broken data, and making sense of old & new metric definitions. I see a lot of potential for such a data discovery tool to be used by all of the technical & non technical personas on this list, as all stakeholders need to see, for example, how margin or retention is calculated.
Data Analyst

Data warehouse movement
Much has been written about the emergence of ELT / ETL and the current players in the space. I don’t have much to add besides highlighting the recent emergence of open-source Fivetran alternatives, Airbyte and Meltano. Whenever I see an open source company, I ask myself the true value of the act of open sourcing & the possibility for monetization down the line. Will creating a community to update connectors vs. having a company do updates in-house prove expedient? Of course, hacker news has strong opinions.
Transformation - pre-aggregation / code
Before data analysts can define metrics, many use dbt or other transformation solutions to clean, re-shape, and pre-aggregate data - easier for a non-engineering user to use than many of the orchestration tools discussed previously. dbt in particular seems to have no immediate plans to move downstream to metric definition, as seen in their recommendation to use LookML (from Looker) to build a metadata layer for SQL queries. Other startups like Deepchannel and Plumbr have been started to make it easier to visualize dbt projects in the broader context of the data pipelines as well as offer “pre-emptive observability” to proactively catch problems from recent changes.
Transformation - SQL for metrics to be used across organization/all apps
In the past year or so, the concept of having a central store of metrics that can be defined easily, served via API, & queried by any application at scale has been dubbed a “metrics store” or “headless BI” (see here for some useful diagrams). Sounds great, right? Just one tool needed to promote organizational alignment across key business metrics! In theory, this would be one of the most useful & sticky tools inside of a company; however, the amount of organizational complexity and context that must be captured by such a tool makes building and selling it very challenging. So much so, there are memes about how each new attempt will be different this time. A few schools of thought exist in terms of who will eventually crack the code - the most popular guesses are a new startup that is “metrics store” / “headless BI”-first or an expansion of materialized views by a startup or even Snowflake itself.
Transformation - SQL for metrics to be visualized inside BI apps
This “next-gen” category is rethinking the traditional act of visualizing metrics to drive business decisions. Though the ecosystem is crowded, while I was at Scale AI, we switched between many different BI tools trying to find the right balance of cost, reliability, UX, and collaboration. I’ve heard many companies similarly “graduate” from tool to tool each year. So, there are likely opportunities to provide tools that better grow with existing users or that involve more users of varying skill levels in the process of metrics definition & usage.

ML Engineer / Data Scientist
Model feasibility & accuracy
This topic definitely deserves its own post with a comprehensive overview of the “ML stack”. As a preview, ML-tooling that is “data-first” can help both with model debugging during training as well as ongoing monitoring of models in production. ML debugging is a new category; only big tech companies have previously had useful platforms to sort through data to find edge cases and make balanced datasets as well as visualize training performance with useful summary statistics. Scale AI’s Nucleus, Aquarium, and W&B give many of these capabilities to startups. ML real-time monitoring, on the other hand, even some larger tech companies don’t have completely figured out. Most current solutions combine academic work (for example, on how to predict & explain why a model isn’t performing well on new data) and monitoring basics, a la “ML Datadog.” Some solutions may even eventually help fix the model.
In addition, some of the hardest challenges for both data scientists & machine learning engineers are getting the input of stakeholders on the importance and feasibility of new models as well as convincing them to devote resources to productionizing models. As a result, supposedly a stark minority of organizations have deployed an ML model in production. “Model application creation” tools have emerged to give data scientists & ML engineers the power of full stack developers, ultimately decreasing time to prototype/production & involving other stakeholders in model development from the MVP phase.
Operations / Go-to-market
Metric / model usage for operations & sales day-to-day
Reverse ETL - moving data out of the warehouse & into business applications - is the next iteration of the Customer Data Platform (e.g. Segment) for enterprises or iPaaS (e.g. Tray, Workato, Zapier) for consumers; ultimately, reverse ETL promises much easier set-up as well as better scalability & complexity management than its predecessors. The companies building reverse ETL have clear value propositions for “operational analytics” use cases - guiding a support team’s prioritization of tickets in Zendesk by including, for example, customer metadata about contract size or sentiment (or even predictions from warehouse-native ML models...). Given the relative newness of the category, I believe the majority of customers still require some education, likely through content, to show the long-term value of these integrations & capture the hearts of technical teams enough to implement a reverse ETL solution. Ultimately, operations & GTM will reap the benefits through more data-driven, faster day-to-day decision making.
Another challenge - as companies grow quickly and have large operations team understaffed with engineering resources, one of three things likely happens: company velocity goes way down, unhappy engineers get looped in for “just one more small task,” or an enterprising operations team member figures out hacks that accumulate as risky tech debt & ultimately break production. Ideally, engineers should be as highly leveraged as possible and operations team members should feel empowered given their first-rate context to act on alerts and update data. However, few widely-used tools exist today with that goal in mind. Many startups have emerged over the past few years making internal tools easier to develop, with various degrees of engineering involvement, vertical specificity, and end user functionality; a clear tradeoff of giving nontechnical users freedom and protecting the overall system against outages exists. From my time working at a hypergrowth startup, even if engineers become much more efficient with better dev tooling, the addressable market here is likely massive.
Final Thoughts & Key Takeaways
As the industry matures, there will be consolidation of data tooling use cases in a smaller number of best-of-breed startups. Perhaps even one start-up can dominate as a true end-to-end data platform (for some customer type/vertical use cases) with a clever long-term expansion strategy.
Data infrastructure opportunities are abundant even though the category is relatively mature. Decreasing developer strife, compute costs, & DevOps headcount required can be massively impactful for most companies, each likely spending the majority of their total data tooling budget on data infrastructure.
Data observability is a new category for an ages-old pain point. People are rightfully excited about possibilities of catching bad data, though ecosystem development is early and a multitude of different approaches exist.
“Next-gen” data governance, data catalogs, and BI tools have clear incumbent solutions with flaws, and they interact with many types of end users, making them attractive entry or expansion areas.
When looking at open source companies, I find it helpful to weigh the pros (community building, rapid adoption, potential hosting monetization play) vs. the cons (monetization challenges, contributor quality control & other maintenance difficulties).
ML data-centric & application tooling is a large part of why FAANG is so far ahead in their roll-out of machine learning. Democratizing tool access has huge usage potential, as more companies begin to consider ML as a serious business driver versus a marketing tactic.
Metrics store/headless BI, reverse ETL, and operations augmentation tooling each require lots of cross-functional business context to be useful, and many products in this category are still being fully developed. However, the higher integration cost as well as closeness to end business results will make such tools sticky inside of organizations.
If you’re working on any products in areas even adjacent to those mentioned in this post, I’d love to chat! My email is leighmarie@foundersfund.com. Though it’s challenging to predict the future - especially in data tooling - I’m very optimistic about many opportunities in the space & always interested in jamming on new approaches.
Thanks to John, Everett, Trae, Alana, Erik, Chip, & Alina for their thoughts & feedback!
Substantive walkthrough, thanks for sharing your notes! Competitive dynamics here remind me of Alex Rampell's "distribution vs innovation". Most notably with emerging point solutions like governance/observability. Data warehouse players (Snowflake/BigQuery etc) have a natural advantage at being in the "starting point" of many organization's data platform. So to the extent that they can bundle/acquire these features faster than new players can get distribution, they could be strongly positioned as the long-term e2e winner. Time will tell.
This is a great read. I’ve given the lateral movement of tools through personas in the Enterprise data landscape some thought but couldn’t have articulated it so well.
Thanks for sharing.